Illustration of Fine-Tuned MLM as Image-Text Quality Scorer

We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g. CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e. CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
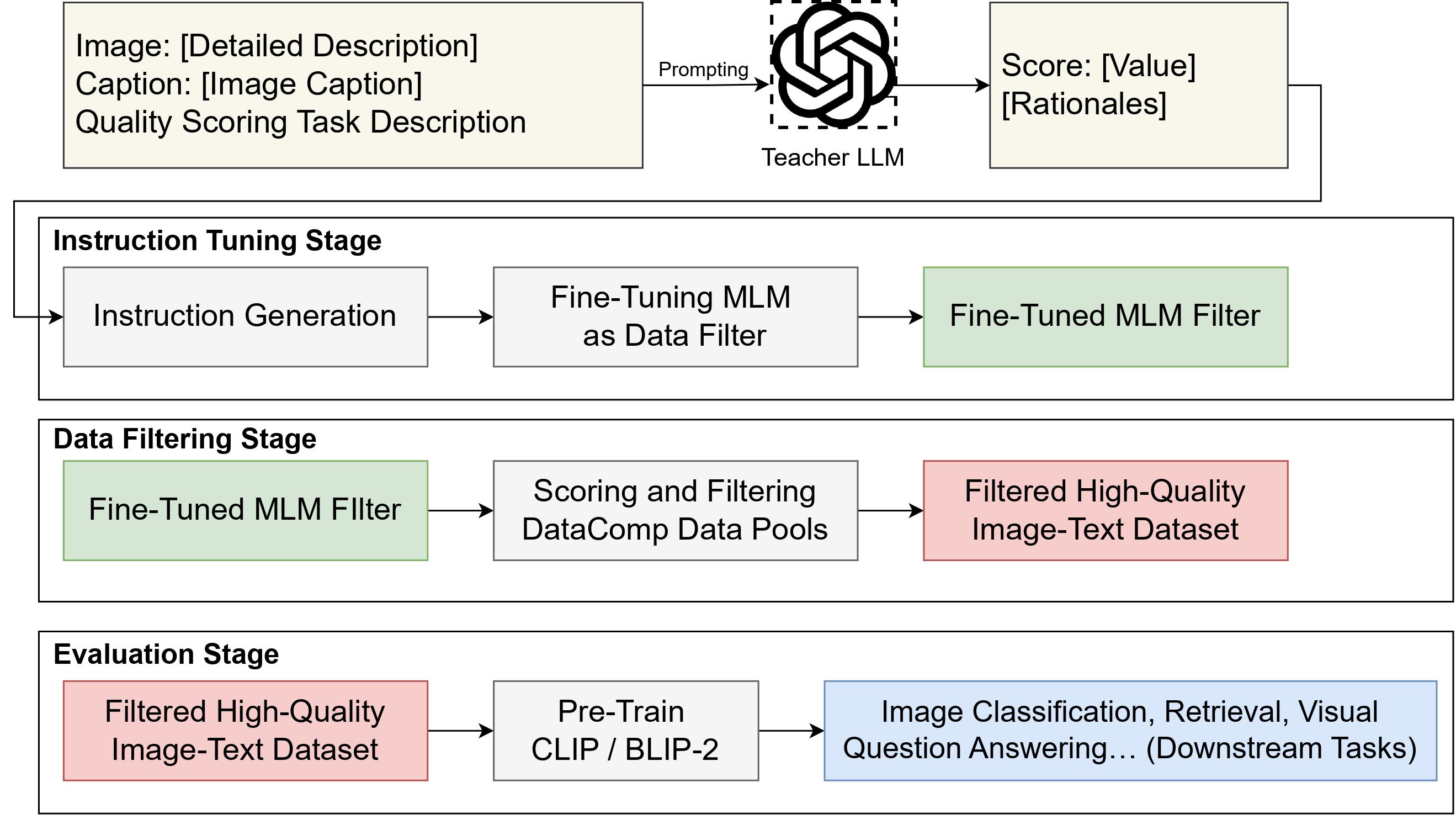
We propose to adopt fine-tuned Multimodal Language Model as effective data filters to select high-quality image-text data to promote the VLM pre-training, which involves three stages:
Defining Metrics for Image-Text Quality Assessment. We defined four different data quality metrics for comprehensive quality assessment of image-text paired data:
Other Data Construction Designs. We use CC12M image-text data as the data resources and then sample 10k image-text pairs based on the clustered text embeddings of captions. We prompt the GPT-4/GPT-4V models using the following templates to construct initial 40k instruction data on 4 quality assessment tasks. Then we uniformly sample 4k instructions from initial 40k intructions based on the integer scores to avoid scoring bias brought by imbalanced fine-tuning. Additionally, we sample another 46k instruction data from LLaVA-665k multimodal instruction set to ensure the diversity of final 50k instruction dataset.
{image}
Text Caption: {caption}
Please evaluate if the provided text caption accurately represents the main features and objects of the image.
The caption doesn't need to detail every aspect of the image, but it should capture its primary theme.
Rate the overall quality of the text caption's match to the image on a scale of 1-100, considering the criteria mentioned.
A higher score indicates higher level of image text matching.
Ensure that your scoring is nuanced and uses the entire range from 0 to 100, reflecting the subtle differences.
The score should be given as an integer, with each number between 0 and 100 considered as a potential score, avoiding the tendency to round to multiples of 10.
Please first output a single line containing the value indicating the scores.
In the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias.
Instruction-Tune Multimodal Language Model as Data Filter. We select LLaVA-13b as the foundation MLM for instruction-tuning on sampled 50k instructions. We directly take the pre-trained checkpoint after pre-training stage-1 of LLaVA and only change the instruction data in stage-2. Please check out our MLM-Filter model at [Model Zoo].
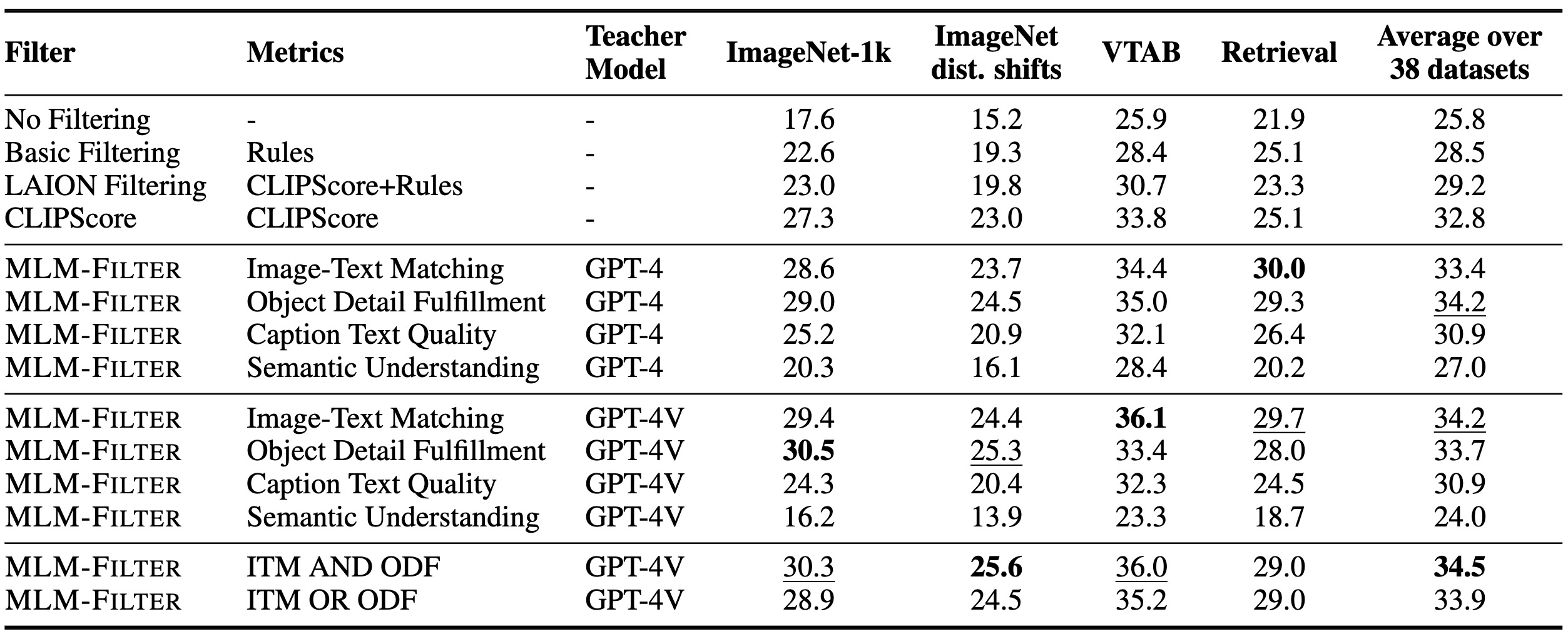
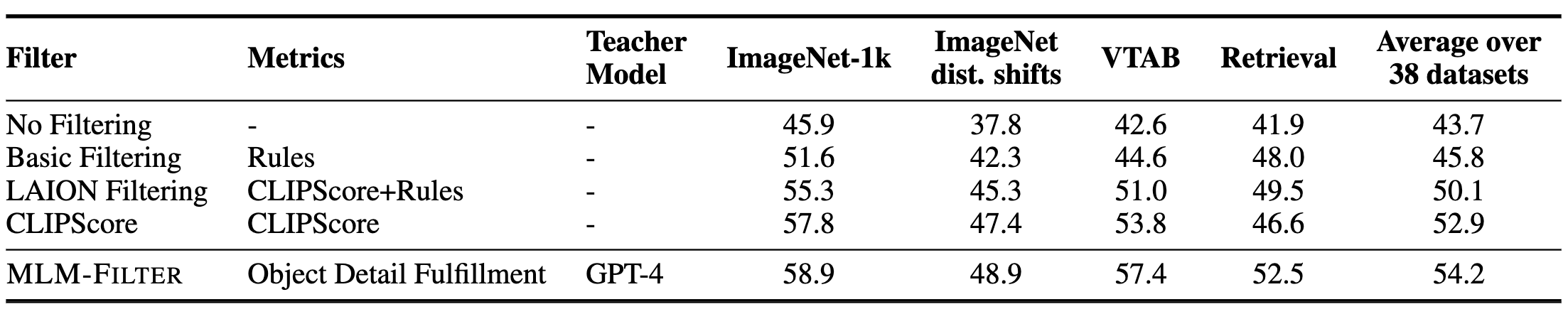
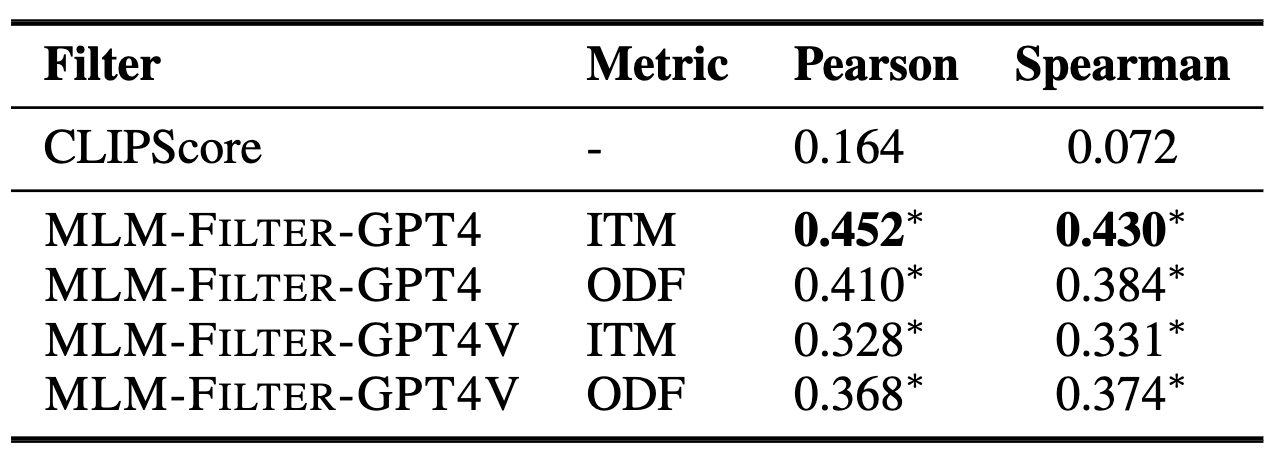
The evaluation results demonstrate the prposed MLM-FILTER can work as more effective filtering method than CLIPScore filter. Additionally, we can draw the following auxiliary conclusions from the results:
@article{mlm-filter,
title={Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters},
author={Wang, Weizhi and Mrini, Khalil and Yang, Linjie and Kumar, Sateesh and Tian, Yu and Yan, Xifeng and Wang, Heng},
publisher={arXiv preprint arXiv:2403.02677},
year={2024},
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. The foundation multimodal language models of our proposed MLM Filter are based on the OpenAI CLIP, Meta LLaMA-2 and its fine-tuned model Vicuna. We also thank LLaVA team to propose the great multimodal language model architecture as well as providing the codebase for further development.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.